
These days Large Language Models (LLMs) are nothing short of revolutionary, though they have been around since 1996 (ELIZA, developed by Joseph Weizenbaum, simulating a psychotherapist in conversation). It always astounds people how these neural network-powered marvels can understand and generate human language with astonishing fluency, opening doors to incredible possibilities. But this power comes at a price. I believe we’re facing a critical juncture: unless we address the security risks head-on, the potential of LLMs could be overshadowed by their vulnerabilities. Let’s start with understanding how do most LLMs respond to user prompts, that we see in daily life:
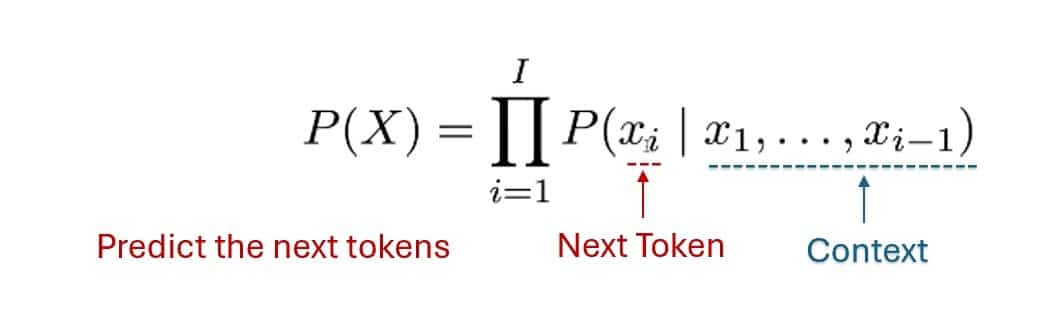
| Figure explaining probabilistic language modelling |
Let’s break down how these models are built. First comes data preparation, where mountains of information are fed to the model. As HuggingFace’s Thomas Wolf astutely points out, data quality is non-negotiable here. It’s the foundation upon which everything else is built. Next is pre-training, where the model starts to grasp the nuances of language. Then, we have fine-tuning, specializing the model for specific tasks. Finally, reinforcement learning from human feedback (RLHF) fine-tunes the model’s outputs, aligning them with our expectations.
Supervised Learning
- You show the child pictures of apples, bananas, and oranges, telling them the name of each fruit.
- Later, when you show a new fruit, the child uses past knowledge to identify it.
Unsupervised Learning
- You give the child a basket of mixed fruits but don’t tell them the names.
- The child starts grouping similar-looking fruits together (e.g., all round ones, all yellow ones).
Reinforcement Learning
- You play a game with the child: If they correctly identify a fruit, they get candy; if they get it wrong, no candy.
- Over time, the child learns to maximize rewards by making better guesses.
But here’s the catch: each stage presents security vulnerabilities. The training method itself—non-federated, federated, or decentralized—introduces distinct risks. Centralized data in non-federated models? A prime target for hackers. Federated training, while more distributed, is susceptible to data poisoning – imagine someone injecting malicious data to subtly corrupt the model’s behavior. And decentralized systems? They expand the attack surface exponentially.
The threats are multifaceted and constantly evolving. Some of them are- data poisoning, where attackers inject corrupt data to skew the model’s outputs. Then there are model inversion attacks, attempts to steal the valuable information the model has learned. Adversarial attacks involve crafting subtle input changes that cause the model to make bizarre or harmful mistakes – think of a self-driving car misinterpreting a stop sign as a green light. And don’t forget prompt injection, where malicious prompts manipulate the model to bypass safety measures or reveal sensitive data. Finally, there’s model theft, where sophisticated techniques are used to steal proprietary LLMs, jeopardizing intellectual property.
These risks aren’t just theoretical. Imagine LLMs generating incredibly convincing phishing emails, automating misinformation campaigns on a massive scale, or being used to create deepfakes that can damage reputations or manipulate elections. The potential for misuse is immense.
This poses a huge challenge for cybersecurity professionals. LLMs can be a powerful tool for defense – automating threat detection, for example – but they can also be easily weaponized. It’s a classic double-edged sword. We need a two-pronged approach: harnessing the power of LLMs for good while simultaneously building robust safeguards against their misuse.
So, where do we go from here? We need comprehensive data vetting, regular security assessments, secure training methods, robust anomaly detection, and, crucially, ethical design principles. But technology alone won’t cut it. We need collaboration – developers, security experts, policymakers, ethicists – all working together to create a safer future for LLMs.
Imagine a world where AI-generated content is indistinguishable from reality. A politician’s voice and face can be replicated with near-perfect accuracy. Fake evidence can be fabricated at scale. At what point does our trust in information collapse?
In the end, it comes down to responsibility. Inventions, no matter how groundbreaking, are neither inherently good nor bad. Nuclear technology can power cities or obliterate them. The internet can connect us or spread misinformation. LLMs are no different. Their impact depends entirely on how we choose to use them. We must be proactive, anticipating and mitigating risks before they materialize. The future of AI, and perhaps much more, depends on it.
About the Author
 Hrishitva Patel is a dedicated professional with a passion for technology, data analytics, and artistic expression. His journey has been a blend of academic achievements, professional growth, and creative exploration.
Hrishitva Patel is a dedicated professional with a passion for technology, data analytics, and artistic expression. His journey has been a blend of academic achievements, professional growth, and creative exploration.
Hrishitva began his academic pursuits at SRM University Kattankulathur (KTR), where he earned a B.Tech, building a strong foundation in engineering. He then advanced his expertise by completing a Master’s in Computer Science at SUNY Binghamton, where he explored cutting-edge technologies and data-driven insights.
Currently, Hrishitva is actively engaged in data analytics and machine learning, applying his skills to uncover meaningful patterns and extract valuable insights from complex datasets. His work focuses on leveraging technology to solve real-world problems and enhance data-driven decision-making.
Seeking a broader understanding of information systems and business strategy, he pursued an MBA at Western Governors University. This experience allowed him to develop leadership skills and gain a comprehensive view of the intersection between technology and business. Furthering his academic journey, Hrishitva has been admitted to the Ph.D. program in Information Systems at the University of Texas at San Antonio (UTSA), where he aims to contribute to the evolving landscape of data and technology research.
Beyond his academic and professional endeavors, Hrishitva finds solace and creative expression in painting. Art serves as a counterbalance to his tech-driven pursuits, allowing him to explore imagination and creativity through colorful strokes on canvas.
Hrishitva embodies the spirit of a lifelong learner, seamlessly integrating his passions for data analytics, technology, and art. His journey continues to evolve, driven by curiosity, innovation, and a commitment to making an impact in his field.
Hrishitva Patel can be reached online at – https://www.linkedin.com/in/hrishitva-patel